Le logiciel R permet d’analyser et de représenter graphiquement des données statistiques, à l’aide d’un langage de programmation spécifique. Son code source est libre et il est gratuitement installable en toute légalité sur les systèmes d’exploitation les plus courants et notamment Linux, Windows et Mac OS X.
Mise en place
Téléchargement et installation
Les fichiers d’installation sont disponibles sur la page du projet CRAN. Des conseils spécifiques pour les différentes plateformes sont donnés en annexes du guide de J.P. Gaudron (chapitre 15). On pourra veiller à demander spécifiquement pendant l’installation l’ajout d’une icône de lancement sur le bureau.
Le programme donne accès à une console, c’est-à-dire un écran texte sur lequel on peut effectuer des commandes en ligne. Mais cette console est un peu déroutante pour un public non averti, par conséquent on pourra surajouter à ce logiciel une interface graphique plus ergonomique telle que :
R Commander, gratuit et installable directement depuis la console avec la commande install.packages("Rcmdr") (voir aussi notes d’installation par John Fox)
RStudio, gratuit dans sa version initiale (très largement suffisante pour une utilisation standard).
En cas d’erreur ou de blocage apparent,
on peut essayer de relancer R en mode administrateur
(possible sous Windows avec un clic droit sur l’icône de lancement)
et afficher plus de messages en spécifiant l’argument
verbose=TRUE dans l’installation de modules,
comme par exemple avec la commande
install.packages("Rcmdr",verbose=TRUE).
De façon générale, l’installation des modules
(avec install.packages) n
’a pas besoin d’être répétée d’une séance à l’autre.
Démarrage
Lors du premier démarrage du logiciel, il est probable qu’un message s’affiche
suggérant l’installation de modules supplémentaires, qu’il suffit d’autoriser.
Sur une plateforme avec des droits d’exécution contrôlés (notamment sous Linux),
on pourra faire ce premier démarrage en mode administrateur
(avec la commande R)
pour que l’installation de ces modules se fasse sans problème.
Le menu « Packages » peut proposer une mise à jour de la liste des modules,
suivie d’une installation des modules manquants.
À chaque ouverture du logiciel R, il faudra
charger les modules utiles
comme R Commander avec la commande :
library(Rcmdr)
Si R Commander ne fonctionne pas,
on peut tout de même accéder à certaines fonctionnalités
avec l’installation et le chargement d’autres modules comme RcmdrMisc.
Remarques générales d’utilisation
Attention, les majuscules et minuscules ne sont pas interchangeables,
y compris à l’intérieur d’un nom de commande.
La définition d’une variable (nombre, texte, liste, jeu de données…)
avec un symbole d’affectation (<- ou =)
ne provoque pas son affichage.
Il faut relancer une commande avec le nom de la variable pour voir sa valeur.
La construction de graphiques réutilise a priori la même fenêtre
qui ne revient pas forcément au premier plan.
On peut concevoir R comme une calculatrice graphique.
Dans la console, on peut écrire un calcul
comme 1+2*3^(4-5)
à la suite du signe supérieur strict (>),
et la touche Entrée lance le calcul dont le résultat s’affiche en dessous,
précédé d’un numéro de ligne.
Ce numéro peut sembler peu intéressant lorsque le résultat tient sur une seule ligne,
mais c’est une information qui deviendra précieuse
lorsque le résultat s’étalera sur plusieurs lignes.
Avec la flèche vers le haut, on peut retrouver les formules écrites précédemment
et les relancer avec d’éventuelles modifications.
Avec R Commander, on dispose d’une fenêtre de script R
dans laquelle on peut écrire les formules, mais on lance leur exécution
à l’aide du bouton « Soumettre » et non pas en appuyant sur la touche Entrée.
Chaque formule soumise apparait alors dans la fenêtre de sortie
avec son résultat en dessous comme dans la console.
Si l’on soumet une formule qui n’a pas de sens
(par exemple si elle se termine par un opérateur comme +),
la zone de message tout en bas signale une erreur avec un numéro d’ordre.
Cela n’empêche pas de corriger sa formule et de la resoumettre.
Les fonctions mathématiques courantes sont disponibles,
comme sqrt (racine carrée),
exp, log (ln),
sin, cos,
tan, round, sum…
Jeu de données
Dans R Commander, le menu « Données → Nouveau jeu de données »
permet de saisir un tableau de valeurs, (appelé Dataset par défaut).
Par exemple, on peut construire un tableau appelé « Mois » avec une colonne « numéro »,
une colonne « nom » et une colonne « jours »
(on pourra se contenter de décrire le cas d’une année non bissextile).
Dans la console, on peut créer ce jeu de données avec la commande
Mois <- data.frame(
numero = c(1:12),
nom = c("janvier", "février", "mars", "avril", "mai", "juin", "juillet",
"aout", "septembre", "octobre", "novembre", "décembre"),
jours = c(31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31))
La fonction c combine les valeurs données en argument
et la notation 1:12 définit l’intervalle d’entiers entre 1 et 12.
On peut aussi récupérer le fichier de données s’il est enregistré dans un répertoire
ou sur un site accessible (comme c’est le cas ici) :
Mois <- read.table("https://boilley.ovh/serveur/Mois.txt", header=TRUE, sep="\t")
Statistiques descriptives élémentaires
La commande summary(Mois)
(accessible dans R Commander par le menu « Statistiques → Résumés → Jeu de données actif »)
fournit le minimum, le maximum, la médiane et les quartiles,
ainsi que la moyenne (mean) des valeurs pour les colonnes numériques.
Pour avoir plus d’indicateurs, R Commander fournit le menu
« Statistiques → Résumés → Statistiques descriptives »
pour afficher notamment l’effectif total (n),
l’écart type (sd),
des quantiles,
l’écart interquartile (IQR)
ΔQ = Q3 − Q1,
le coefficient de variation (cv) ou écart relatif,
le coefficient de dissymétrie (skewness),
le coefficient d’aplatissement ou kurtosis),
l’erreur type de la moyenne (se).
Le module RcmdrMisc permet d’obtenir ces résultats par
La fonction with
permet d’indiquer le jeu de données avec lequel on travaille. On aurait pu commencer directement avec la fonction c, en remplaçant chaque occurrence de la variable jours par Mois$jours.
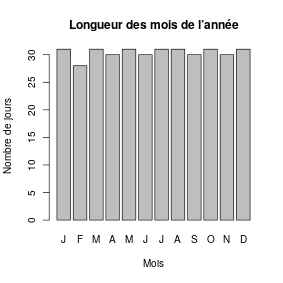
Diagrammes en bâtons et en barres
Depuis le menu « Graphes → Graphe d'une variable numérique discrète », on peut
répresenter les effectifs pour chaque longueur de mois
en sélectionnant la variable « jours » dans l’onglet « Données ».
Les options permettent de graduer l’axe des ordonnées en pourcentage
plutôt qu’en nombre d’occurrences (appelé classiquement « fréquence » en statistique
même si cette appellation ne correspond pas à la notion mathématique).
On pourra d’ailleurs renommer l’axe des ordonnées en « Nombre de mois »
si l’on choisit la graduation frequency.
Sortie graphique pour la fonction discretePlot
La fenêtre de script montre la commande qui définit la construction
du diagramme en bâtons pour cette variable numérique discrète.
with(Mois, discretePlot(jours, xlab="Nombre de jours", ylab="Nombre de mois"))
La fonction discretePlot
conduit à la création du diagramme en bâtons.
Les variables xlab et ylab
permettent de modifier l’allure du diagramme. Si cette fonction n’est pas disponible, on peut la simuler avec la commande :
with(Mois, plot(table(jours), xlab="Nombre de jours", ylab="Nombre de mois"))
La fonction table calcule le tableau de contingence associé à une ou plusieurs variables. En l’occurrence, la commande table(Mois$jours) seule récapitule le nombre de mois par nombre de jours.
On peut comparer le rendu de la fonction plot et celui de la fonction barplot qui trace un diagramme en barres,
avec des colonnes plus épaisses juxtaposées sans tenir compte de la valeur en abscisse.
Sortie graphique pour la fonction barplot
Cette nouvelle fonction est mieux adaptée pour montrer les longueurs de mois en l’appliquant à la variable jours. Il faut dans ce cas adapter les variables xlab, ylab et main (pour le titre du graphique).
On peut faire apparaitre les noms des mois en abscisse avec l’argument
names.arg=nom,
indiquer juste l’initiale du nom du mois en majuscule en remplaçant l’expression
nom par toupper(substr(nom,1,1)),
voire changer la couleur des barres avec un argument
col="nomdecouleur"
(le nom de couleur doit être en anglais et entre guillemets).
Sauvegarde
Le jeu de données peut être sauvegardé depuis le menu
« Données → Jeu de données actif → Enregistrer le jeu de données actif »
pour une réutilisation dans R.
save("Mois", file="nomdufichier.RData")
Il peut aussi être exporté depuis le menu
« Données → Jeu de données actif → Exporter le jeu de données actif »
pour une utilisation avec d’autres programmes
(notamment avec les tableurs LibreOffice Calc, Gnumeric ou Excel).
Dans les deux cas, on prendra garde au choix du séparateur de colonnes et au séparateur décimal.
Le séparateur de colonnes le plus pratique est la tabulation,
qui a peu de risque d’être confondue avec un caractère de texte courant.
Pour une utilisation avec LibreOffice, on prendra la virgule comme séparateur décimal.
Le graphe courant peut être sauvegardé depuis le menu
« Graphes → Enregistrer le graphe dans un fichier », ce qui correspond à une commande de la forme :
Il faut éventuellement adapter les paramètres width et height pour définir la taille de l’image, et augmenter au besoin le paramètre res pour accrotre
On peut ensuite récupérer un jeu de données existant à partir du menu
« Données → Charger un jeu de données » ou importer jeu de données
(notamment un fichier CSV qui peut être produit par un tableur)
à partir du menu « Données → Importer des données ».
Comme à l’enregistrement, on veillera à renseigner correctement
le séparateur de colonnes et le séparateur décimal.
TP2 : lettres
La fréquence d’utilisation des lettres du français varie selon le contexte d’écriture (dialogue, roman, encyclopédie…) Le corpus de Wikipédia en français permet de définir le jeu de données suivant :
où la fonction strsplit décompose la chaine de caractères donnée en premier argument le long des séparateurs donnés en deuxième argument
et la fonction unlist simplifie la liste obtenue pour pouvoir l’intégrer proprement dans le jeu de données. La combinaison de ces deux fonctions permet de produire rapidement une colonne dont les éléments sont des caractères isolés, comme ici le codage de voyelle ou consonne.
Les deux variables donnant la lettre et le type sont définies comme des facteurs, car elles ne prennent qu’un petit nombre de valeurs que l’on peut ordonner. On renomme d’ailleurs les valeurs du type avec la dernière ligne du script.
On peut ici refaire un résumé statistique qui donnera notamment la moyenne et l’écart type des fréquences des lettres.
Histogramme, nuage de points et diagramme circulaire
La variable fq n’est pas discrète mais continue, et peut être représentée par un histogramme par le menu « Graphes → Histogramme », avec la fonction Hist, ou avec la commande :
hist(Alphabet$fq, xlab="Fréquence (%)", ylab="Nombre de lettres",
col="darkgrey", main="Répartition des lettres par fréquence")
Les fréquences individuelles des lettres de l’alphabet pourraient être représentées à l’aide d’un diagramme en barres ou avec un nuage de points. On retrouve la syntaxe habituelle dans le code suivant :
with(Alphabet, plot(lettre, fq, ylab="Fréquence (%)",
main="Fréquence des lettres de l’alphabet sur Wikipédia"))
Figuration des points du graphique par la lettre correspondante
Si l’on obtient un message d’erreur du type 'xlim' nécessite des valeurs finies,
c’est que la variable lettre n’a pas été enregistrée comme facteur.
On peut y remédier avec la commande
Alphabet["lettre"] <- factor(Alphabet$lettre).
On peut aussi remplacer la variable lettre en abscisse par l’intervalle 1:26, mais dans ce cas on ne voit plus directement où est représentée chaque lettre. On peut alors effacer les valeurs de l’axe des abscisses avec l’argument xaxt="n", cacher les points avec l’argument type="n" et rajouter les lettres au graphique avec la fonction text. On enchaine la construction du graphique et le placement des lettres grâce à des accolades.
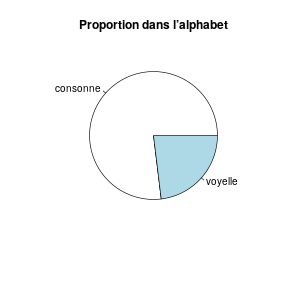
On peut aussi construire un diagramme circulaire (plus communément appelé « camembert ») à partir du menu « Graphes → Graphe en camembert », avec le titre « Proportion dans l’alphabet », ce qui devrait correspondre à la commande :
with(Alphabet, pie(table(type), labels=levels(type),
main="Proportion dans l’alphabet"))
Diagramme circulaire
Dans ce diagramme, les angles des secteurs sont calculés à partir des effectifs de chaque type (donnés par la fonction table) et les étiquettes sont les modalités correspondantes (données par la fonction levels). Les couleurs peuvent être adaptées avec col=c("red","lightblue"). On peut préférer un démarrage en haut avec rotation dans le sens des aiguilles d’une montre par l’argument clockwise=TRUE.
Pour représenter la distribution des lettres sur Wikipédia, on peut reprendre la commande précédente en remplaçant les effectifs de types par la colonne de fréquences (fq) et les étiquettes par des lettres (lettre). On veillera également à remplacer le titre principal du diagramme (main).
Statistiques par groupe
On peut comparer les indicateurs statistiques des voyelles et ceux des consonnes. Avec R Commander, le menu « Statistiques → Résumés → Statistiques descriptives » comprend un bouton « Résumer par groupes » qui permet de spécifier la variable type.
On peut télécharger le fichier dpt2018.csv depuis le site de l’INSEE (conditions de vie et société)
et l’importer avec la commande :
Base <- read.csv2("chemin/d’accès/à/remplacer/dpt2018.csv", encoding="UTF-8"")
On évitera d’utiliser ici le menu de R Commander qui utilise la fonction read.table au lieu de read.csv.
Sous Windows ou Mac OS, on peut remplacer les barres obliques (backslashes\) du chemin d’accès par les barres de division (/).
La norme d’encodage doit être spécifiée pour une bonne gestion des accents dans les prénoms (même si ceux-ci sont tous en majuscules !)
Si l’import ne fonctionne pas en local, on peut la récupérer avec le chemin
https://boilley.ovh/serveur/dpt2018.csv
Le fichier ainsi chargé est très volumineux. La fonction head permet de visualiser ses premières lignes.
head(Base)
Cela permet de constater que certaines lignes ne contiennent pas d’année de naissance ni de numéro de département. On peut aussi obtenir la structure de la base :
On voit alors les noms des différentes colonnes, le type de leurs contenus (int pour des entiers, chr pour des chaines de caractères,
Factor pour des entités identifiables. Ici les années de naissance et les numéros de département ne sont pas considérés comme des entiers à cause de leur valeur codée X sur certaines lignes.
Réencodage et filtration
On renomme les colonnes sans mettre d’accents dans les variables pour éviter les problèmes d’encodage sur certaines plateformes.
La fonction str montre bien qu’un niveau a disparu des facteurs annee et dpt.
Séries temporelles
ExerciceAgréger les nombres de naissances par année dans un jeu de données appelé Chronologie et en faire un diagramme en barres.
Le graphique obtenu permet de distinguer les chutes de naissances lors des deux guerres mondiales, le baby boom et la crise pétrolière. On peut mettre en évidence les décennies à l’aide d’un cycle de couleurs comme celui défini par l’argument suivant.
ExerciceConstruire un jeu de données MonPrenom en filtrant les lignes qui concernent son propre prénom (en majuscules et avec les accents éventuels) pour calculer ensuite l’évolution du nombre de naissances associées depuis 1900 et la représenter avec un diagramme en barres. Commenter l’allure du diagramme obtenu par comparaison avec l’évolution du nombre totale de naissances.
Pour un prénom relativement récent, l’intervalle de temps pourra être assez réduit par rapport à l’étendue du XXe siècle.
Pour un prénom plus ancien, une partie des fluctuations sur l’attribution du prénom pourra provenir des fluctuations sur le nombre de naissances. On pourra alors essayer de calculer la proportion annuelle du prénom dans l’ensemble des naissances, en s’assurant d’abord que toutes les années soient prises en compte, en créant la fonction suivante.
L’évolution du prénom Christophe s’obtient alors avec la commande chronoprenom("Christophe"). Attention, le résultat de cette fonction est sensible à la présence d’accents.
Pyramide et courbe
On peut vérifier l’équilibre annuel entre les sexes à la naissance construisant un tableau de contigence des variables sexe et annee, que l’on transforme en jeu de données.
On peut construire ensuite un graphique en pyramide qui n’est pas une pyramide des âges ! en installant le module pyramid au besoin.
library(pyramid)pyramid(Parite, Llab="H", Rlab="F", Clab="Année", Cstep=10, Laxis=100*(0:4),
main="Nombre de naissances par an et par sexe en milliers")
La surreprésentation masculine qui apparait dans la deuxième moitié du XXe siècle peut être mieux mise en évidence avec une courbe.
with(Parite, plot((M-F)/(M+F), type="l"))
La courbe semble montrer une stabilisation de la différence de proportions à 5 % de la population totale, ce qui revient à une différence de 10 % entre la natalité des filles et celle des garçons.
Cartes géographiques
Au lieu d’étudier la répartition chronologique des naissances, on peut étudier leur répartition géographique.
ExerciceCréer un jeu de données Repartition qui agrege les nombres de naissances par département.
Pour visualiser cette répartition, on va charger la carte des départements de France métropolitaine avec le module raster.
On peut éventuellement apprécier le découpage de la France ainsi réalisé avec la commande plot(formes). Il ne reste qu’à associer aux zones de la carte les effectifs de naissances correspondants.
L’index idx ainsi créé peut être réutilisé pour représenter d’autres cartes, par exemple la prévalence d’un prénom dans l’ensemble des naissances par département.
TP4 : données territoriales
On peut récupérer la base de données comparateur de territoires de l’INSEE, l’ouvrir avec un tableur et la réenregistrer au format CSV en éliminant les 5 premières lignes pour que les données puissent être interprétées correctement.